
When it comes to application performances, bottlenecks like waiting too long for a specific page to load or triggering an API call which never returns – are easy to spot. In those cases it is obvious where problems are and where most of the execution time was spent. Of course, it is totally different thing, will you be able to resolve the noticed performance issues or not.
On the other side, there are many places in the application where time can be spent. Some used tools and libraries we take for granted and do not expect our logic is spending significant time running within them. This is a story about one specific case, in which application logic takes a lot of time to execute and how a simple change using HikariCP helped to cut the execution time in half.
Connection Pooling
Many applications you worked with, had a need to use some database. Opening and closing the connection to the database is usually an expensive operation. That is where the database connection pooling comes in place. The application opens couple of connections to the database, keeps them open and reuses them for different read/write operations against the database. There are different Java connection pool implementations, like DBCP (2), C3P0, to name a few.
HikariCP
HikariCP is a very fast lightweight Java connection pool. As advertised, HikariCP is a “zero-overhead” production-quality connection pool. The API and overall code base are relatively small and highly optimized. It also does not cut corners for performance like many other Java connection pool implementations. It order to achieve such performances, developers when down to bytecode-level engineering, and beyond. HikariCP contains many micro-optimizations that individually are barely measurable, but together combine as a boost to overall performance. Some of these optimizations are measured in fractions of a millisecond amortized over millions of invocations. See more details at Down the Rabbit Hole.
About Pool Sizing
How big should your connection pool be? You might be surprised that the question is not “how big” but rather “how small”! Check the article on HikariCP Wiki and watch the video on connection pool sizing.
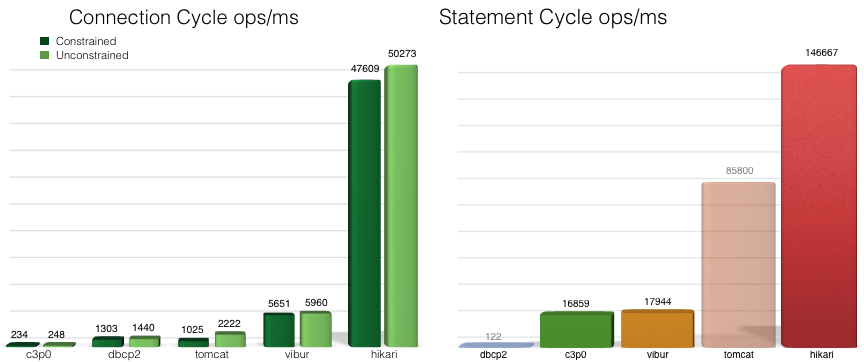
How HikariCP Helped Us
Importing data from different sources is a common requirement nowadays. In the project, we had an import procedure which needs to atomically persist about 100K objects. And it takes time to parse input data, prepare object for persisting (or updating) and finally storing all the changes to the database. The application is based on a more-less standard Java, Spring, Hibernate, PostgreSQL technical stack. The application is running under Apache Tomcat 8.5. Data source is a Tomcat resource, using DBCP2 connection pool.
Each object is mapped (by Hibernate) to multiple relational SQL statements, each committed separately. Regular DB operations, executed by the application users, are performing OK and fast. But bulk operations, like importing 100K objects, take some significant time. In this case, there are a lot of SQL statements, commits and DB transactions to perform. During one of our brainstorming sessions, when we analyzed how to improve performance of the import procedure, idea came out to try utilizing a different connection pool.
We did not expect much, but just a simple change to HikariCP, as Tomcat JDBC connection pool resource, made our import procedure to finish 2 times faster. It is really amazing how very small things adds up, when applied multiple times. And how easy is for one to overlook that.
If you’re going to store large amounts of important information, you better make sure that you do it in a way that’s scalable and maintainable.
Thank you for your comment! I completely agree. There is always a place for improvements, though we have spent a lot of efforts in defining and unifying the import interface and import process pipeline(s).